ACTU
Nvidia et le futur du cloud
 par CBL,
email @CBL_Factor
par CBL,
email @CBL_Factor
En termes de CPUs, AMD a fini par dépasser Intel sur tous les tableaux (rapport prix/performance, rapport puissance/performance) et dans tous les secteurs depuis les ordinateurs portables jusqu'aux serveurs. Mais en termes de GPUs, AMD se traîne encore derrière Nvidia. Les cartes à base de RDNA 2 (embarquées dans la PS5 et la XSeX) pourraient changer la donne mais Nvidia vient de présenter sa nouvelle architecture Ampère. Et oui j'écris Ampère avec un accent grave car le nom vient d'un physicien français.
Elle fait suite à Turing qui équipe les RTX 20xx et les GTX 16xx. Pour l'instant, un seul GPU a été annoncé le A100. C'est ce qu'Nvidia appelle un "accélérateur", à savoir une puce sur la quelle vous ne brancherez pas votre moniteur, mais dont vous en collerez une pelletée dans vos serveurs pour faire des calculs et du rendu en ligne. C'est le successeur du V100 fondé sur l'architecture Volta dont vous n'avez probablement pas entendu parler vu qu'Nvidia n'a pas produit de cartes grand public. Détaillons.
Commençons par une série de chiffres. Ceux du V100 sont entre parenthèses:
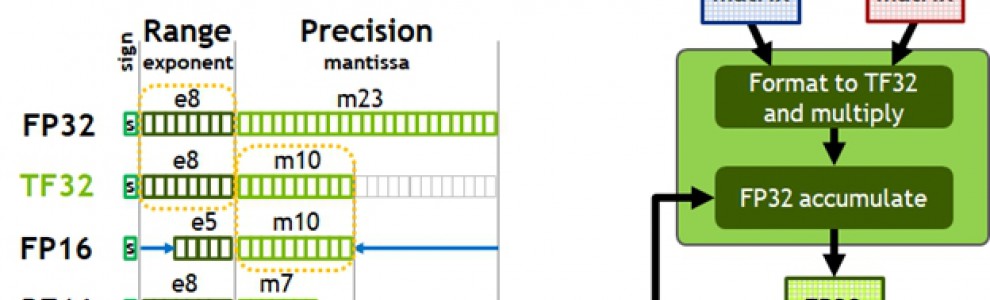
Mais surtout, les tensor cores d'Ampère supportent des nouveaux types de données qui étaient auparavant traitées par le GPU "classique" comme les nombres flottants en simple précision. Ces derniers sont super importants car ils sont devenus la norme en matière d'IA. Pour les traiter sur ses tensor cores, Ampère utilise un tour de passe-passe en utilisant un format de données internes appelé TF32, mais qui fait disparaître au passage une partie de la précision en les transformant en pseudo-FP16. Ampère peut traiter 156 mille milliards d'opérations par seconde (TFLOPS) sur ces TF32.
"Mais CBL je m'en cogne de tout cela. Qu'est-ce que cela va apporter dans les jeux ?". J'y arrive. Les mêmes tensor cores ou probablement une forme limitée arriveront dans les RTX 30xx, les cartes de joueurs qui seront dévoilées plus tard cette année. Ces tensor cores sont de plus en plus utilisés par les jeux. Pour le ray-tracing, ils servent à limiter le nombre de rayons utilisés en reconstruisant les pixels manquants. Avec le DLSS, ils permettent d'upscaler le rendu en haute résolution avec une qualité proche du natif. Récemment, Nvidia les a utilisés pour supprimer le bruit ambiant. Et ce n'est que le début.
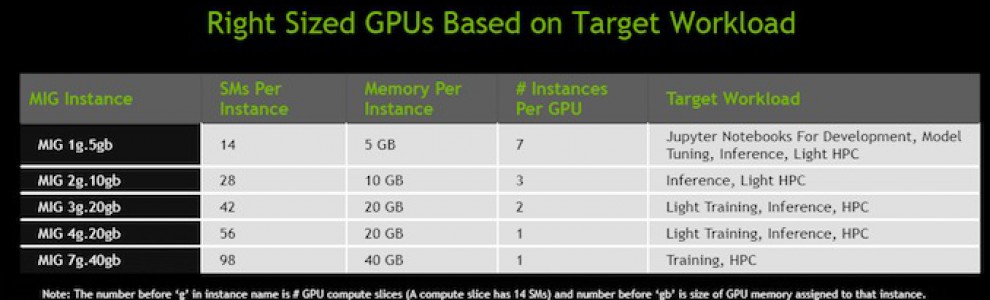
Mais LA grosse nouveauté d'Ampère est ce qui s'appelle multi-instance GPU ou MIG. On sait virtualiser des CPU depuis fort longtemps à savoir que les coeurs d'un CPU physique peuvent être séparés et assignés à plusieurs machines virtuelles différentes tournant en même temps. Du coup un CPU à 8 coeurs par exemple permet aux marchands de nuages type Amazon de louer 8 serveurs à 1 coeur. MIG permet de faire pareil pour les GPUs. Un GPU A100 peut être divisé en 7 GPUs virtuels disposant chacun de leurs propres coeurs, de leur propre bande passante mémoire, de leur propre mémoire vidéo et de leur propre mémoire cache.
Les conséquences pour le jeu dans le nuage (Stadia, Shadow, GeForce Now...) sont énormes. A la place de devoir disposer d'un GPU par joueur, les fournisseurs de nuage vont pouvoir utiliser le même GPU pour plusieurs instances diminuant ainsi la place, le coût et la consommation. Si en plus ils utilisent le DLSS, ils peuvent rendre les jeux en résolution moindre réduisant encore plus le coût GPU.
Pour ceux qui se posent la question, il n'y a aucun avantage à avoir un GPU AMD en combo avec un CPU AMD sur PC. Le CPU n'a aucune idée de quel GPU présent. Il se contente de faire des appels à l'API graphique. Le DGX A100, le serveur de calcul d'Nvidia embarquant 8 A100, utilise même des CPUs AMD ! La raison est simple : les CPUs Intel ne supportent toujours pas le PCI Express Gen 4.
Elle fait suite à Turing qui équipe les RTX 20xx et les GTX 16xx. Pour l'instant, un seul GPU a été annoncé le A100. C'est ce qu'Nvidia appelle un "accélérateur", à savoir une puce sur la quelle vous ne brancherez pas votre moniteur, mais dont vous en collerez une pelletée dans vos serveurs pour faire des calculs et du rendu en ligne. C'est le successeur du V100 fondé sur l'architecture Volta dont vous n'avez probablement pas entendu parler vu qu'Nvidia n'a pas produit de cartes grand public. Détaillons.
Commençons par une série de chiffres. Ceux du V100 sont entre parenthèses:
- 7nm pour la finesse de gravure (12nm)
- 6912 coeurs CUDA tournant à 1,41 GHz (5120 à 1,53 GHz)
- 40 Go de VRAM HBM2 (16 or 32 selon les modèles)
- Un mémoire bus de 5120 bits (4096)
- 1,6 To/s de bande passante mémoire (0.9)
- 54,2 milliards de transistors répartis sur 826 mm2 (21,1 sur 815mm2)
- 400W (300 ou 350 selon les modèles)
- 19.5 TFLOPS de puissance en simple précision alias FP32 pour les coeurs CUDA (15.7)
Mais surtout, les tensor cores d'Ampère supportent des nouveaux types de données qui étaient auparavant traitées par le GPU "classique" comme les nombres flottants en simple précision. Ces derniers sont super importants car ils sont devenus la norme en matière d'IA. Pour les traiter sur ses tensor cores, Ampère utilise un tour de passe-passe en utilisant un format de données internes appelé TF32, mais qui fait disparaître au passage une partie de la précision en les transformant en pseudo-FP16. Ampère peut traiter 156 mille milliards d'opérations par seconde (TFLOPS) sur ces TF32.
"Mais CBL je m'en cogne de tout cela. Qu'est-ce que cela va apporter dans les jeux ?". J'y arrive. Les mêmes tensor cores ou probablement une forme limitée arriveront dans les RTX 30xx, les cartes de joueurs qui seront dévoilées plus tard cette année. Ces tensor cores sont de plus en plus utilisés par les jeux. Pour le ray-tracing, ils servent à limiter le nombre de rayons utilisés en reconstruisant les pixels manquants. Avec le DLSS, ils permettent d'upscaler le rendu en haute résolution avec une qualité proche du natif. Récemment, Nvidia les a utilisés pour supprimer le bruit ambiant. Et ce n'est que le début.
Mais LA grosse nouveauté d'Ampère est ce qui s'appelle multi-instance GPU ou MIG. On sait virtualiser des CPU depuis fort longtemps à savoir que les coeurs d'un CPU physique peuvent être séparés et assignés à plusieurs machines virtuelles différentes tournant en même temps. Du coup un CPU à 8 coeurs par exemple permet aux marchands de nuages type Amazon de louer 8 serveurs à 1 coeur. MIG permet de faire pareil pour les GPUs. Un GPU A100 peut être divisé en 7 GPUs virtuels disposant chacun de leurs propres coeurs, de leur propre bande passante mémoire, de leur propre mémoire vidéo et de leur propre mémoire cache.
Les conséquences pour le jeu dans le nuage (Stadia, Shadow, GeForce Now...) sont énormes. A la place de devoir disposer d'un GPU par joueur, les fournisseurs de nuage vont pouvoir utiliser le même GPU pour plusieurs instances diminuant ainsi la place, le coût et la consommation. Si en plus ils utilisent le DLSS, ils peuvent rendre les jeux en résolution moindre réduisant encore plus le coût GPU.
Pour ceux qui se posent la question, il n'y a aucun avantage à avoir un GPU AMD en combo avec un CPU AMD sur PC. Le CPU n'a aucune idée de quel GPU présent. Il se contente de faire des appels à l'API graphique. Le DGX A100, le serveur de calcul d'Nvidia embarquant 8 A100, utilise même des CPUs AMD ! La raison est simple : les CPUs Intel ne supportent toujours pas le PCI Express Gen 4.